import requests
import folium
import matplotlib.pyplot as pltGet timeseries from COGs
Demonstrates gathering a timeseries of statistics for a given area using the Raster API
Run this notebook
You can launch this notbook using mybinder, by clicking the button below.
![]()
Approach
- Using a list of STAC items and a bouding box fetch stats from
/cog/statisticsendpoint - Generate a timeseries plot using statistics from each time step
- Speed up workflow using Dask
Declare your collection of interest
You can discover available collections the following ways:
- Programmatically: see example in the
list-collections.ipynbnotebook - JSON API: https://staging-stac.delta-backend.com/collections
- STAC Browser: http://veda-staging-stac-browser.s3-website-us-west-2.amazonaws.com
STAC_API_URL = "https://staging.openveda.cloud/api/stac"
RASTER_API_URL = "https://staging.openveda.cloud/api/raster"
collection_id = "no2-monthly"Fetch STAC collection
We will use requests to fetch all the metadata about the collection of interest from STAC.
collection = requests.get(f"{STAC_API_URL}/collections/{collection_id}").json()
collection{'id': 'no2-monthly',
'type': 'Collection',
'links': [{'rel': 'items',
'type': 'application/geo+json',
'href': 'https://staging.openveda.cloud/api/stac/collections/no2-monthly/items'},
{'rel': 'parent',
'type': 'application/json',
'href': 'https://staging.openveda.cloud/api/stac/'},
{'rel': 'root',
'type': 'application/json',
'href': 'https://staging.openveda.cloud/api/stac/'},
{'rel': 'self',
'type': 'application/json',
'href': 'https://staging.openveda.cloud/api/stac/collections/no2-monthly'}],
'title': 'NO₂',
'extent': {'spatial': {'bbox': [[-180, -90, 180, 90]]},
'temporal': {'interval': [['2016-01-01 00:00:00+00',
'2023-12-31 00:00:00+00']]}},
'license': 'MIT',
'renders': {'dashboard': {'bidx': [1],
'title': 'VEDA Dashboard Render Parameters',
'assets': ['cog_default'],
'rescale': [[0, 15000000000000000]],
'resampling': 'bilinear',
'color_formula': 'gamma r 1.05',
'colormap_name': 'rdbu_r'}},
'providers': [{'url': 'https://disc.gsfc.nasa.gov/',
'name': 'NASA Goddard Earth Sciences Data and Information Services Center',
'roles': ['producer', 'processor']},
{'url': 'https://www.earthdata.nasa.gov/dashboard/',
'name': 'NASA VEDA',
'roles': ['host']}],
'summaries': {'datetime': ['2016-01-01T00:00:00Z', '2023-12-31T00:00:00Z']},
'description': 'Darker colors indicate higher nitrogen dioxide (NO₂) levels and more activity. Lighter colors indicate lower levels of NO₂ and less activity. Missing pixels indicate areas of no data most likely associated with cloud cover or snow.',
'item_assets': {'cog_default': {'type': 'image/tiff; application=geotiff; profile=cloud-optimized',
'roles': ['data', 'layer'],
'title': 'Default COG Layer',
'description': 'Cloud optimized default layer to display on map'}},
'stac_version': '1.0.0',
'stac_extensions': ['https://stac-extensions.github.io/item-assets/v1.0.0/schema.json',
'https://stac-extensions.github.io/render/v1.0.0/schema.json'],
'dashboard:is_periodic': True,
'dashboard:time_density': 'month'}Describe the periodic nature of the data
In the collection above we will pay particular attention to the fields that define the periodicity of the data.
collection["dashboard:is_periodic"]Truecollection["dashboard:time_density"]'month'collection["summaries"]{'datetime': ['2016-01-01T00:00:00Z', '2023-12-31T00:00:00Z']}Fetch STAC items
Get the list of all the STAC items within this collection.
items = requests.get(
f"{STAC_API_URL}/collections/{collection_id}/items?limit=100"
).json()["features"]
len(items)96We can inspect one of these items to get a sense of what metadata is available.
items[0]{'id': 'OMI_trno2_0.10x0.10_202312_Col3_V4.nc',
'bbox': [-180.0, -90.0, 180.0, 90.0],
'type': 'Feature',
'links': [{'rel': 'collection',
'type': 'application/json',
'href': 'https://staging.openveda.cloud/api/stac/collections/no2-monthly'},
{'rel': 'parent',
'type': 'application/json',
'href': 'https://staging.openveda.cloud/api/stac/collections/no2-monthly'},
{'rel': 'root',
'type': 'application/json',
'href': 'https://staging.openveda.cloud/api/stac/'},
{'rel': 'self',
'type': 'application/geo+json',
'href': 'https://staging.openveda.cloud/api/stac/collections/no2-monthly/items/OMI_trno2_0.10x0.10_202312_Col3_V4.nc'},
{'title': 'Map of Item',
'href': 'https://staging.openveda.cloud/api/raster/collections/no2-monthly/items/OMI_trno2_0.10x0.10_202312_Col3_V4.nc/map?bidx=1&assets=cog_default&rescale=0%2C15000000000000000&resampling=bilinear&color_formula=gamma+r+1.05&colormap_name=rdbu_r',
'rel': 'preview',
'type': 'text/html'}],
'assets': {'cog_default': {'href': 's3://veda-data-store-staging/no2-monthly/OMI_trno2_0.10x0.10_202312_Col3_V4.nc.tif',
'type': 'image/tiff; application=geotiff; profile=cloud-optimized',
'roles': ['data', 'layer'],
'title': 'Default COG Layer',
'description': 'Cloud optimized default layer to display on map',
'raster:bands': [{'scale': 1.0,
'nodata': -1.2676506002282294e+30,
'offset': 0.0,
'sampling': 'area',
'data_type': 'float32',
'histogram': {'max': 32579336984854530,
'min': -6736120943476736.0,
'count': 11.0,
'buckets': [30.0,
409205.0,
23559.0,
1376.0,
430.0,
277.0,
119.0,
35.0,
18.0,
5.0]},
'statistics': {'mean': 331445868796687.44,
'stddev': 935114136625544.4,
'maximum': 32579336984854530,
'minimum': -6736120943476736.0,
'valid_percent': 82.97996520996094}}]},
'rendered_preview': {'title': 'Rendered preview',
'href': 'https://staging.openveda.cloud/api/raster/collections/no2-monthly/items/OMI_trno2_0.10x0.10_202312_Col3_V4.nc/preview.png?bidx=1&assets=cog_default&rescale=0%2C15000000000000000&resampling=bilinear&color_formula=gamma+r+1.05&colormap_name=rdbu_r',
'rel': 'preview',
'roles': ['overview'],
'type': 'image/png'}},
'geometry': {'type': 'Polygon',
'coordinates': [[[-180, -90],
[180, -90],
[180, 90],
[-180, 90],
[-180, -90]]]},
'collection': 'no2-monthly',
'properties': {'proj:bbox': [-180.0, -90.0, 180.0, 90.0],
'proj:epsg': 4326.0,
'proj:shape': [1800.0, 3600.0],
'end_datetime': '2023-12-31T00:00:00',
'proj:geometry': {'type': 'Polygon',
'coordinates': [[[-180.0, -90.0],
[180.0, -90.0],
[180.0, 90.0],
[-180.0, 90.0],
[-180.0, -90.0]]]},
'proj:transform': [0.1, 0.0, -180.0, 0.0, -0.1, 90.0, 0.0, 0.0, 1.0],
'start_datetime': '2023-12-01T00:00:00'},
'stac_version': '1.0.0',
'stac_extensions': ['https://stac-extensions.github.io/projection/v1.0.0/schema.json',
'https://stac-extensions.github.io/raster/v1.1.0/schema.json']}Define an area of interest
We will be using a bounding box over metropolitan france. We’ll use that bounding box to subset the data when calculating the timeseries.
france_bounding_box = {
"type": "Feature",
"properties": {"ADMIN": "France", "ISO_A3": "FRA"},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[-5.183429, 42.332925],
[8.233998, 42.332925],
[8.233998, 51.066135],
[-5.183429, 51.066135],
[-5.183429, 42.332925],
]
],
},
}Let’s take a look at that box.
m = folium.Map(
location=[40, 0],
zoom_start=3,
)
folium.GeoJson(france_bounding_box, name="France").add_to(m)
mMake this Notebook Trusted to load map: File -> Trust Notebook
Use /cog/statistics to get data for the AOI
First, we create a generate_stats function and then we call it with the bounding box defined for France.
# the bounding box should be passed to the geojson param as a geojson Feature or FeatureCollection
def generate_stats(item, geojson):
result = requests.post(
f"{RASTER_API_URL}/collections/{collection_id}/items/{item['id']}/statistics",
json=geojson
).json()
return {
**result["properties"],
"start_datetime": item["properties"]["start_datetime"],
}Generate stats
This may take some time due to the complexity of the shape we’re requesting. See the end of this notebook for tips on how to speed this up.
%%time
stats = [generate_stats(item, france_bounding_box) for item in items]CPU times: user 317 ms, sys: 64.9 ms, total: 382 ms
Wall time: 1min 26sInspect one result
stats[0]{'statistics': {'cog_default_b1': {'min': -387779578036224.0,
'max': 5971174383157248.0,
'mean': 1636077207936257.2,
'count': 11880.0,
'sum': 1.9436597230282736e+19,
'std': 808762440624020.6,
'median': 1506456557846528.0,
'majority': 1143241374171136.0,
'minority': -387779578036224.0,
'unique': 11875.0,
'histogram': [[120.0,
1616.0,
4274.0,
3441.0,
1384.0,
624.0,
244.0,
125.0,
40.0,
12.0],
[-387779578036224.0,
248115831504896.0,
884011241046016.0,
1519906650587136.0,
2155802060128256.0,
2791697603887104.0,
3427592744992768.0,
4063488422969344.0,
4699383564075008.0,
5335279242051584.0,
5971174383157248.0]],
'valid_percent': 100.0,
'masked_pixels': 0.0,
'valid_pixels': 11880.0,
'percentile_2': 395780397465600.0,
'percentile_98': 3847018581590016.0}},
'ADMIN': 'France',
'ISO_A3': 'FRA',
'start_datetime': '2023-09-01T00:00:00+00:00'}Plot timeseries
It is easier to interact with these results as a pandas dataframe. The following function takes the json, passes it to pandas, cleans up the column names and parses the date column.
import pandas as pd
def clean_stats(stats_json) -> pd.DataFrame:
df = pd.json_normalize(stats_json)
df.columns = [col.replace("statistics.cog_default_b1.", "") for col in df.columns]
df["date"] = pd.to_datetime(df["start_datetime"])
return df
df = clean_stats(stats)Construct the plot
fig = plt.figure(figsize=(20, 10))
plt.plot(df["date"], df["mean"], "black", label="Mean monthly NO2 values")
plt.fill_between(
df["date"],
df["mean"] + df["std"],
df["mean"] - df["std"],
facecolor="lightgray",
interpolate=False,
label="+/- one standard devation",
)
plt.plot(
df["date"],
df["min"],
color="blue",
linestyle="-",
linewidth=0.5,
label="Min monthly NO2 values",
)
plt.plot(
df["date"],
df["max"],
color="red",
linestyle="-",
linewidth=0.5,
label="Max monhtly NO2 values",
)
plt.legend()
plt.title("NO2 Values in France (2016-2022)")Text(0.5, 1.0, 'NO2 Values in France (2016-2022)')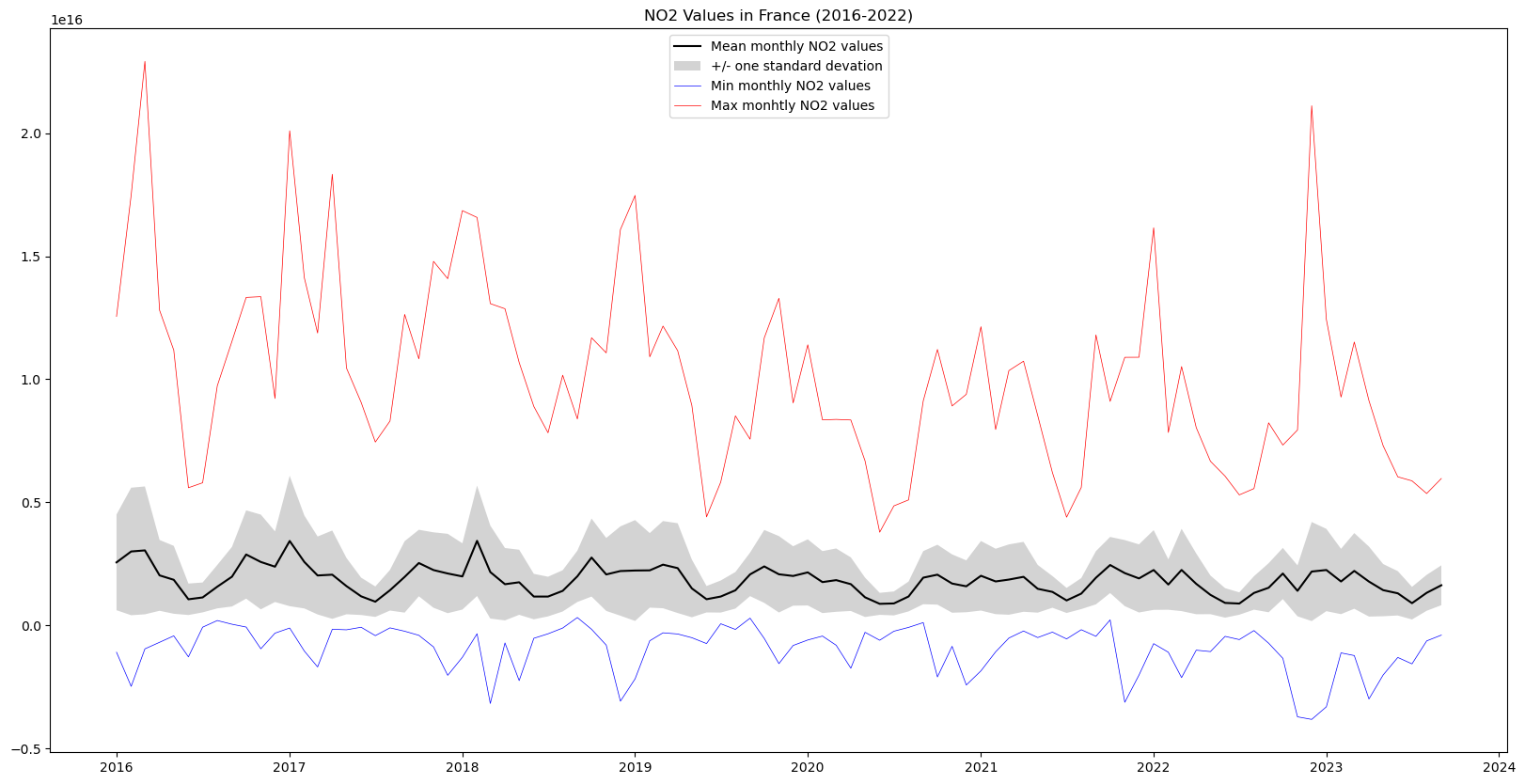
In this graph we can see the yearly cycles in NO2 values due to seasonal variations, as well as a slight downward slope in maximum NO2 values
Complex AOI
The values plotted above don’t correspond exactly to Fance, since the bounding box excludes Corsica and overseas territories such as Mayotte and French Polynesia, and covers parts of neighboring countries including Spain, Italy, Germany and the entirety of Luxembourg. We can fetch GeoJSON from an authoritative online source (https://gadm.org/download_country.html).
While the NO2 values above correspond more or less to those of in France, we can be much more precise by using a complex geojson that represents the boundaries of France exactly, including overseas territories in the Carribean and Indian Oceans, and South America.
Note: In this notebook we write out the whole perimeter as a MultiPolygon in geojson. In practice you will often be reading this kind of shape from a file (usually with the help of geopandas).
response = requests.get(
"https://geodata.ucdavis.edu/gadm/gadm4.1/json/gadm41_FRA_0.json"
)
# If anything goes wrong with this request output error contents
assert response.ok, response.text
result = response.json()
print(f"There are {len(result['features'])} features in this collection")There are 1 features in this collectionThat is the geojson for a feature collection, but since there is only one feature in it we can grab just that.
france_aoi = result["features"][0]Let’s take a look at this AOI on a map
m = folium.Map(
location=[40, 0],
zoom_start=3,
)
folium.GeoJson(france_aoi, name="France").add_to(m)
mMake this Notebook Trusted to load map: File -> Trust Notebook
We can now request the NO2 values for this complex AOI the same way as for the bounding box.
Notice, however, that due to the complexity of the shape, it takes much longer to gather the requested data about 4 times as long as for the bounding box example above.
%%time
aoi_df = clean_stats([generate_stats(item, france_aoi) for item in items])CPU times: user 4.02 s, sys: 73.9 ms, total: 4.09 s
Wall time: 2min 27sWe can compare the mean monthly NO2 values calculated when using the bounding box and when using the country’s exact borders
fig = plt.figure(figsize=(20, 10))
plt.plot(
df["date"],
df["mean"],
color="blue",
label="Mean monthly NO2 values using bounding box",
)
plt.plot(
aoi_df["date"],
aoi_df["mean"],
color="red",
label="Mean monthly NO2 values using complex AOI",
)
plt.legend()
plt.title("NO2 Values in France (2016-2022)")Text(0.5, 1.0, 'NO2 Values in France (2016-2022)')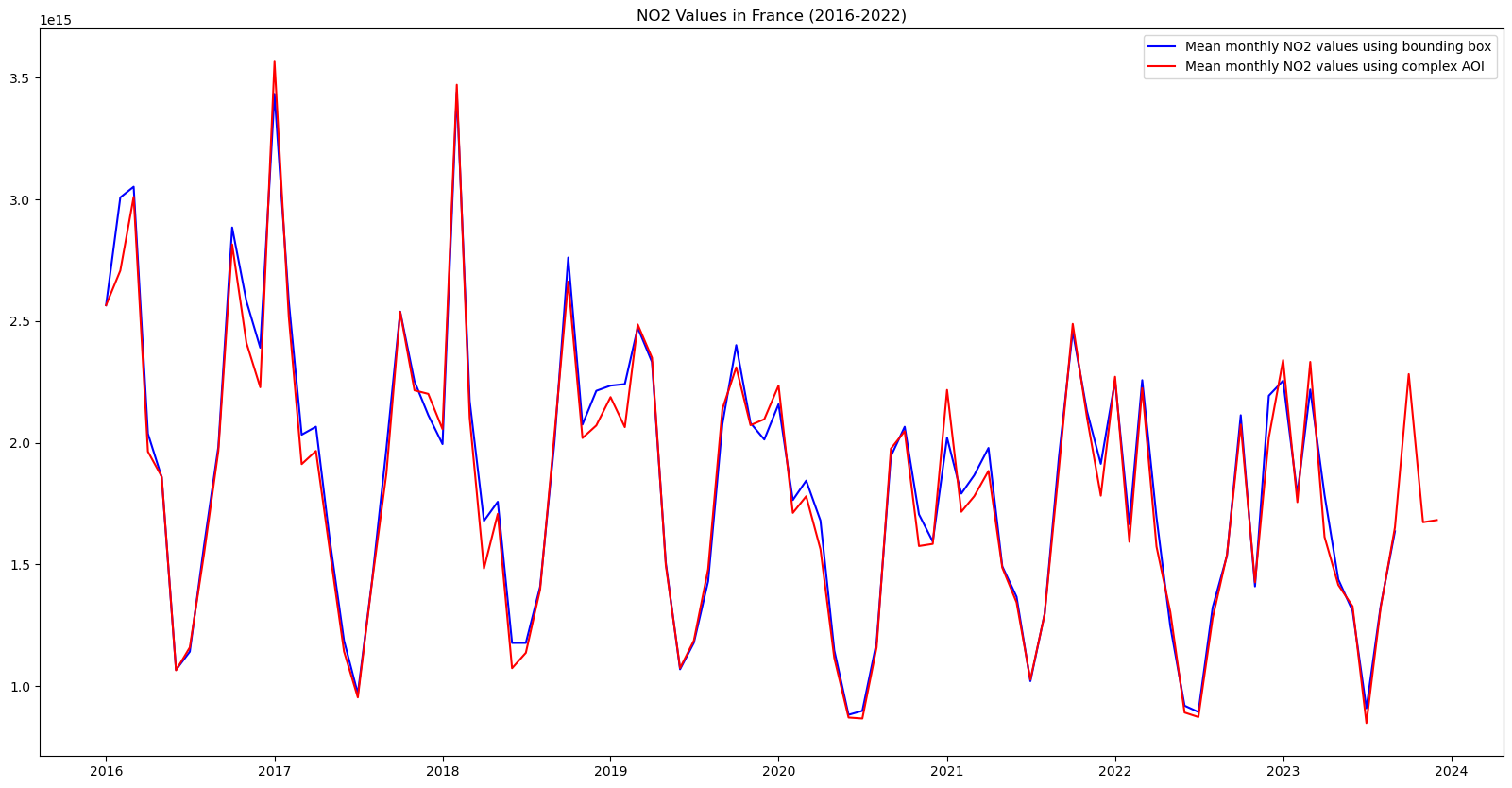
While the difference is small, it is very interesting to note that the NO2 values calculated using the exact borders are systematically less than when using the bounding box. This may be due to the fact that the bounding box includes parts of western Germany and northern Italy that have a lot industrial activity, whereas the areas included when using the exact borders that are not included in the bounding box case, are overseas territories much less industrial activity.
Speed things up: parallelize computation with Dask
We can drastically reduce the time it takes to generate the timeseries, even with the complex AOI above, by parallelizing our code. The cogs/statistics API is powered by AWS Lambda which executes each request in a separate instance. This means the requests are highly scalable. Since each statistics request is for a single timestamp, we can request statistics for multiple timesteps concurrently, and greatly reduce the amount of time needed. We will demonstrate this by using the Dask.
Create a Dask client
First we will create a Dask client. In this case we will use the threads on the same server that is running this jupyter notebook.
import dask.distributed
client = dask.distributed.Client()Submit work
We will submit the generate_stats function for each item in our list and collect a list of futures. This will immediately kick off work in dask. We can then gather all the results.
%%time
futures = [client.submit(generate_stats, item, france_aoi) for item in items]
stats = client.gather(futures)CPU times: user 23.6 s, sys: 483 ms, total: 24.1 s
Wall time: 45.2 sClose the Dask client
It is good practice to close the client when you are done.
client.shutdown()
Alternate approach
If you are familiar with the concurrent.futures library you can use that instead of Dask.